MixDiff: Mixing Natural and Synthetic Images for
Robust Self-Supervised Representations
WACV 2025
- Univeristy of Colorado Boulder1
- INRIA, Paris2
- University of California Irvine3
*Joint first authors
Abstract
This paper introduces MixDiff, a new self-supervised learning (SSL) pre-training framework that combines real and synthetic images. Unlike traditional SSL methods that predominantly use real images, MixDiff uses a variant of Stable Diffusion to replace an augmented instance of a real image, facilitating the learning of cross real-synthetic image representations. Our key insight is that while models trained solely on synthetic images underperform, combining real and synthetic data leads to more robust and adaptable representations. Experiments show MixDiff enhances SimCLR, BarlowTwins, and DINO across various robustness datasets and domain transfer tasks, boosting SimCLR's ImageNet-1K accuracy by 4.56%. Our framework also demonstrates comparable performance without needing any augmentations, a surprising finding in SSL where augmentations are typically crucial. Furthermore, MixDiff achieves similar results to SimCLR while requiring less real data, highlighting its efficiency in representation learning.
Mixing in joint-embedding SSL
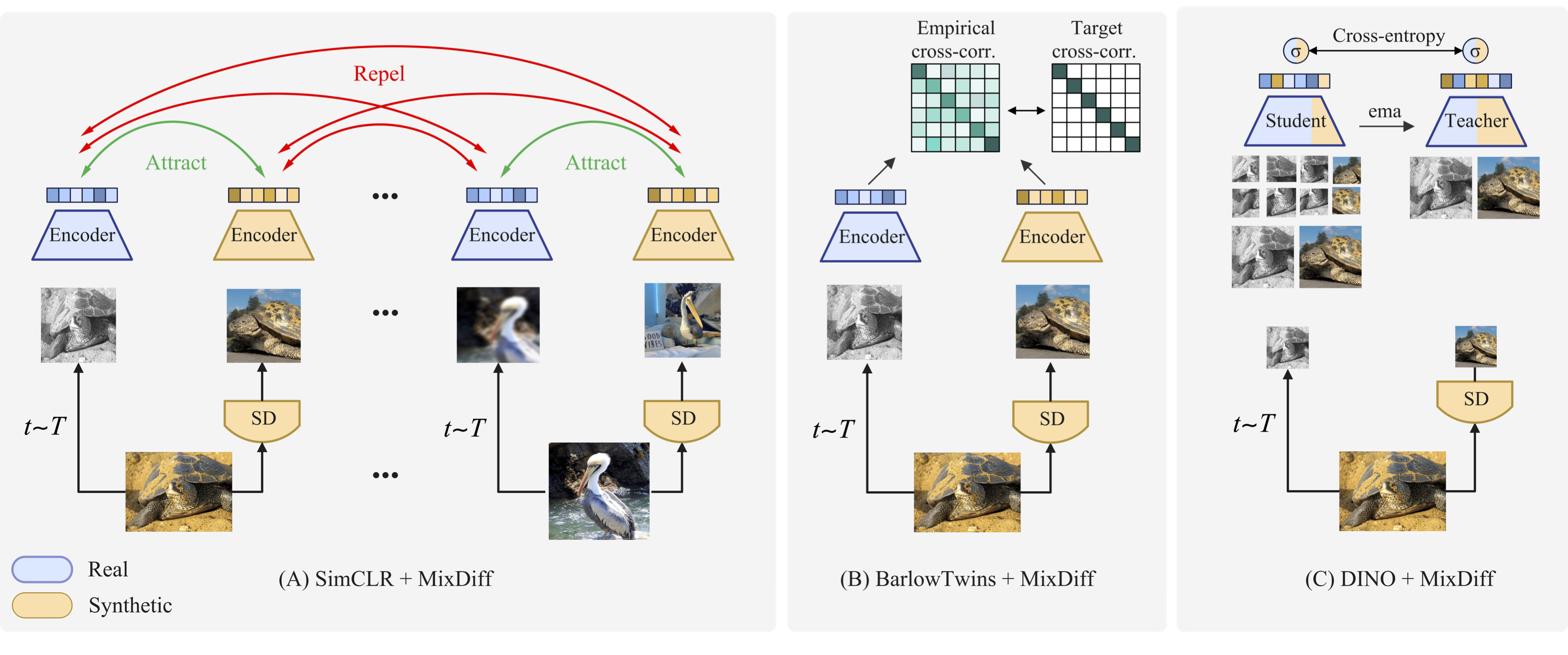
Consider \(x_1\) and \(x'_1\), two augmented patches from an image, randomly selected from a dataset. These augmentations can include a variety of changes, such as altering spatial positions within an image, adding varying noise and applying random color adjustments, etc. Existing instance-based discriminative SSL methods primarily rely on real images (example - MoCo, SimCLR, BarlowTwins, and DINO). In these methods, the representation derived from the first augmentation, \(x_1\), of a real image is anticipated to closely align with the representation of the second augmentation, \(x_1\)$, of the same image. Our MixDiff framework modifies this approach by incorporating synthetically generated images alongside real ones. The primary objective of MixDiff is to synchronize the representations of real and synthetic images, thus enhancing existing SSL methodologies such as SimCLR, DINO, and BarlowTwins.
MixDiff boosts robustness to distribution shifts
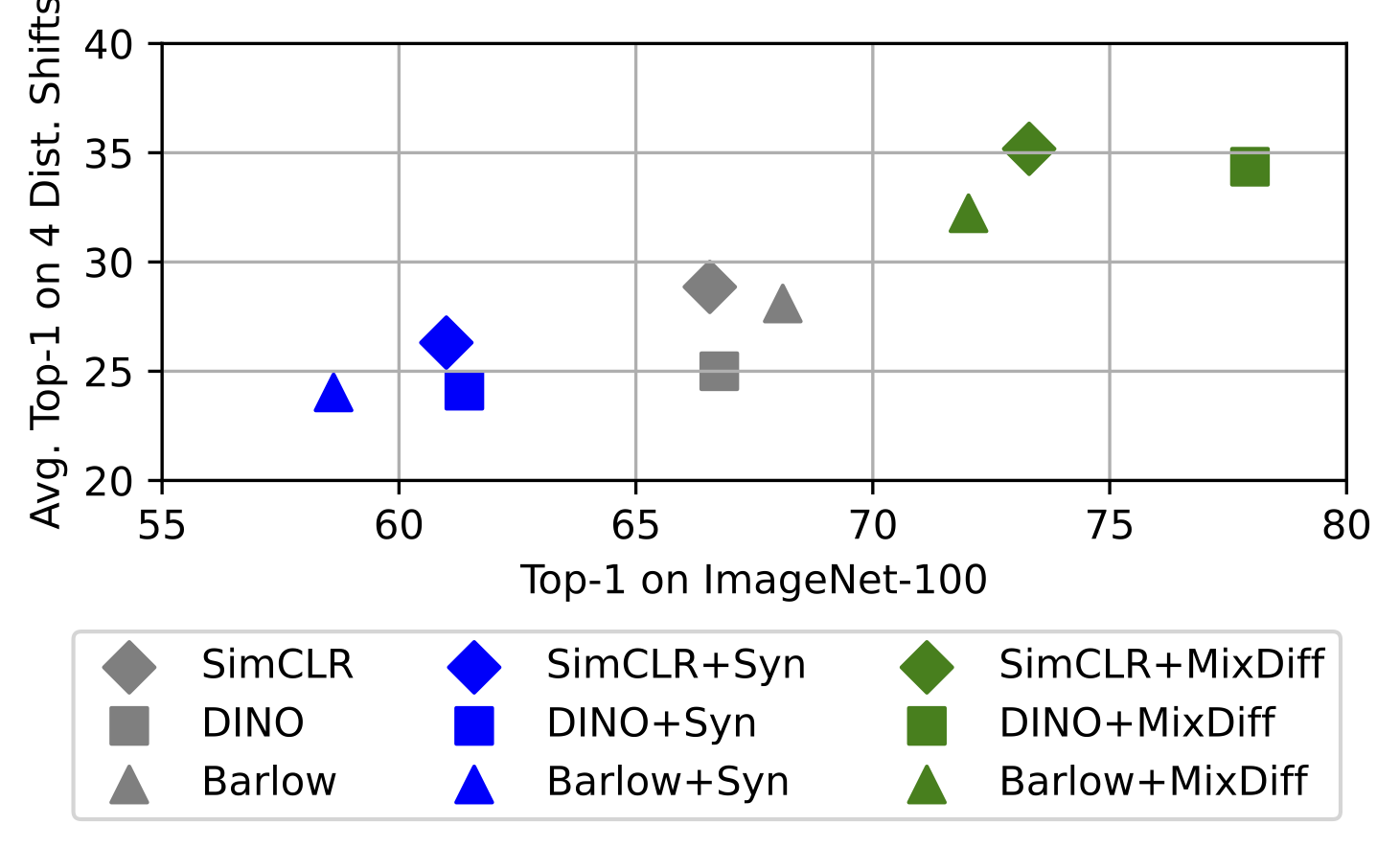
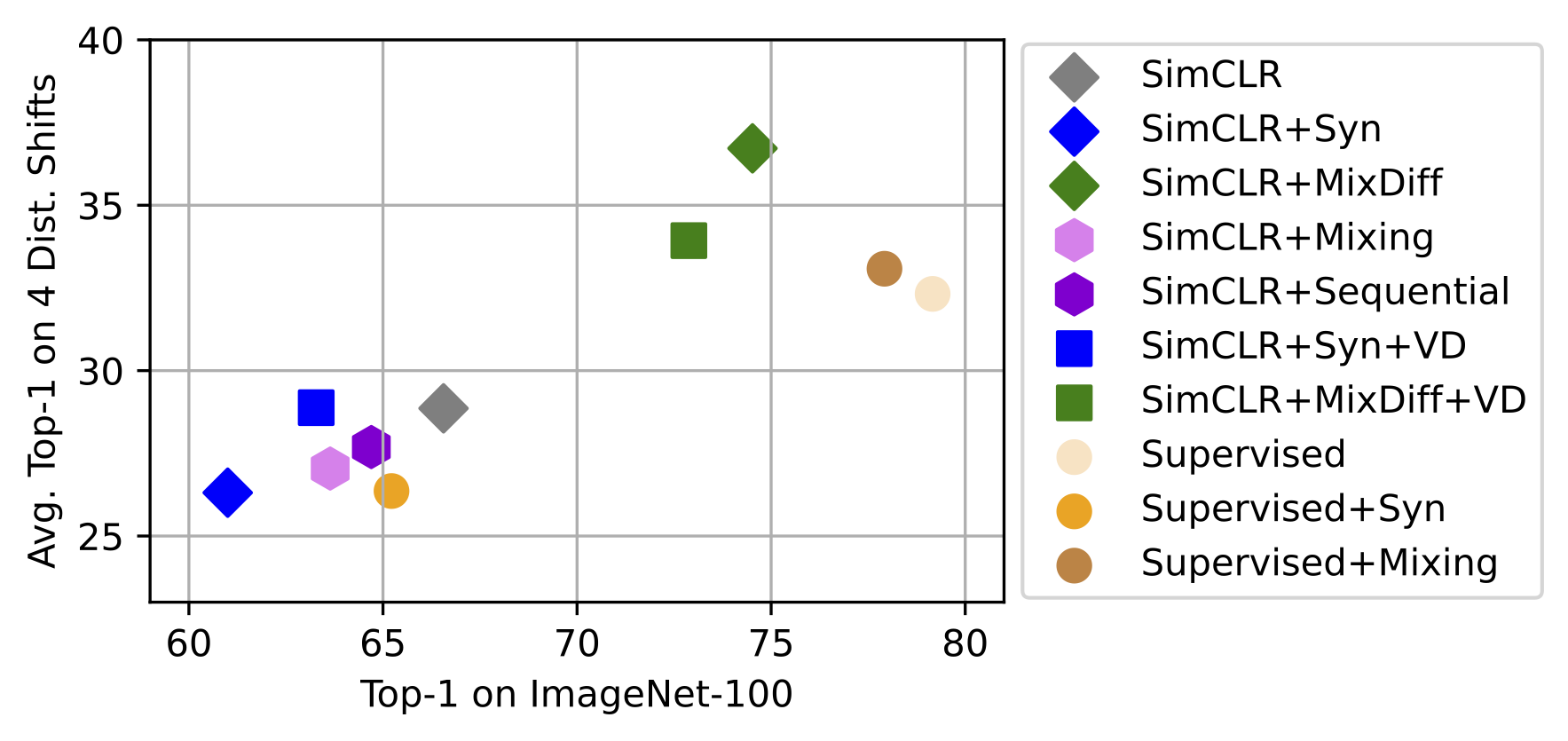
To evaluate performance under domain shifts, we choose a set of four datasets including ImageNet-A, ImageNet-Sketch, ObjectNet, ImageNet-V2, VizWiz-Classification, and ImageNet-R. We also evaluate the feature generality of the models by conducting transfer learning experiments across various image datasets and compare MixDiff’s effectiveness with other models as shown in figure to the right. The above figure shows Top-1 classification accuracies (%) for various models on ImageNet-100 (x-axis) and the average of four domain shift datasets (y-axis). It compares the performance of models trained on real, synthetic (Syn), and an equal combination of real and synthetic images (MixDiff). Models in the top-right quadrant exhibit better in-distribution and out-of-distribution accuracies. We observe that MixDiff outperforms in-distribution and also enhances robustness against distribution shifts datasets. We believe MixDiff's effectiveness is due to synthetic images acting as hard positive samples. It is more challenging to bring generated images closer than to bring augmented samples closer. These hard positive samples prevent the model from learning trivial features, which enhances its ability to learn effective representatio
DINO: Impact of mixing in self-attention and performance

In our analysis of DINO models trained on IN-100, we interpret masks derived from self-attention maps by applying thresholds for enhanced visualization. These maps, sourced from the top-performing head of each ViT-S/16 DINO model trained on both real and synthetic ImageNet datasets using our MixDiff approach, are not designed for mask creation but rather to highlight the model's focus areas during image processing. Our findings show that models trained on real images effectively segment objects with some background attention. In contrast, the model trained on synthetic images shows a tendency to focus less on the background, but the overall object segmentation appears somewhat less defined. The MixDiff-trained model strikes a balance, demonstrating clearer object focus with minimal background distraction, indicating improved object segmentation. This improvement is clearly visible in the last row. This suggests that integrating synthetic data with the MixDiff method potentially enhances scene understanding and image segmentation capabilities.
We believe MixDiff’s effectiveness is due to synthetic images acting as hard positive samples. It is more challenging to bring generated images closer than to bring augmented samples closer. These hard positive samples prevent the model from learning trivial features, which enhances its ability to learn effective representations
Overall, we find that SSL models pre-trained exclusively on synthetic images underperform compared to those pre-trained with real images across most scenarios. Interestingly, our proposed MixDiff, which uses both real and synthetic images, improves model performance in SSL not only on in-distribution datasets but also on various out-of-distribution tasks, suggesting enhanced representation learning. Specifically, we observe an average increase in top-1 accuracy of about 26.92% across six distributional datasets and a 7.36% improvement in transfer learning across eight datasets. This observation suggests that while synthetic images alone may be insufficient for optimal pre-training, MixDiff capitalizes on the synergistic approach of leveraging the strengths of both image types to learn more robust SSL representations. Check out our paper for more details.
Citation
If you want to cite our work, please use:
@article{bafghi2024mixing,
title={Mixing Natural and Synthetic Images for Robust Self-Supervised
Representations},
author={Bafghi, Reza Akbarian and Harilal, Nidhin and
Monteleoni, Claire and Raissi, Maziar},
journal={arXiv preprint arXiv:2406.12368},
year={2024}
}